Enterprise cached secondary storage with unique architecture
In the digital world we have become accustomed to the fact that data is the key asset for many enterprises. We understand that data is valuable and the applications use advanced architectures in the primary storage area. We are also aware of the factbackup must also be properly designed. Typical backup approach is not enough anymore.
So how does modern backup work?
Historically tape drives were a perfect backup choice when tape cartridges provided capacities unavailable for other storage media. The increase and diversity of data was not so rapid and the simple backup nature was to save all data at subsequent iterations.
It was part of the characteristics of tape solution that tapes drives worked great with uniformly large data streams.
Today the nature of the data, it’s growth, distributed systems, various characteristics of data processing require a change in the approach to backup strategy. This leads us to enterprise architecture of cached secondary storage.
But this is only part of the solution. Fast and spacious backup storage is no longer enough to effectively store and protect data. The classic High Availability &Disaster Recovery solutions are difficult to implement and are expensive. Customers expect flexible solutions that are able to dynamically scale horizontally and vertically, dynamically increase capacity or redundancy or expand to another datacenter when required.
Technologies implemented in PEBYTE Backup Appliance solutions:
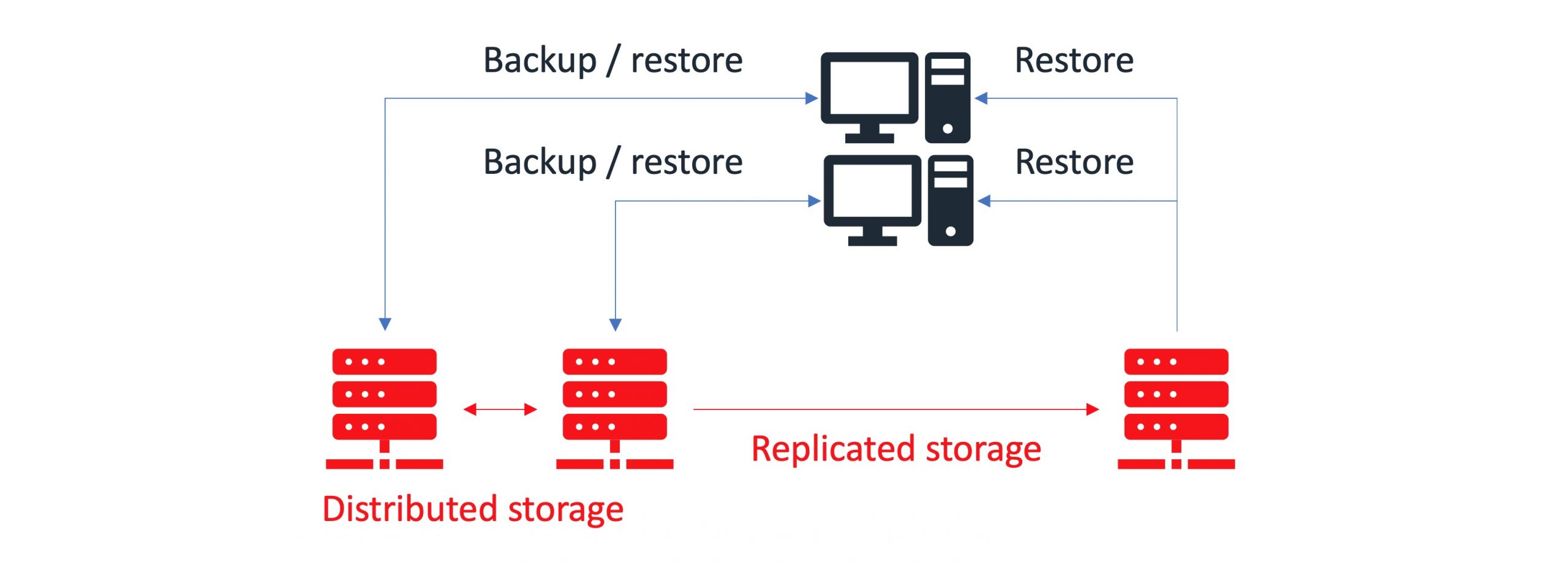
Distributed storage
Distributed storage diffuses data across multiple physical appliances. You can use distributed storage where the requirement is to scale storage and the redundancy is addressed by architecture of application layers.
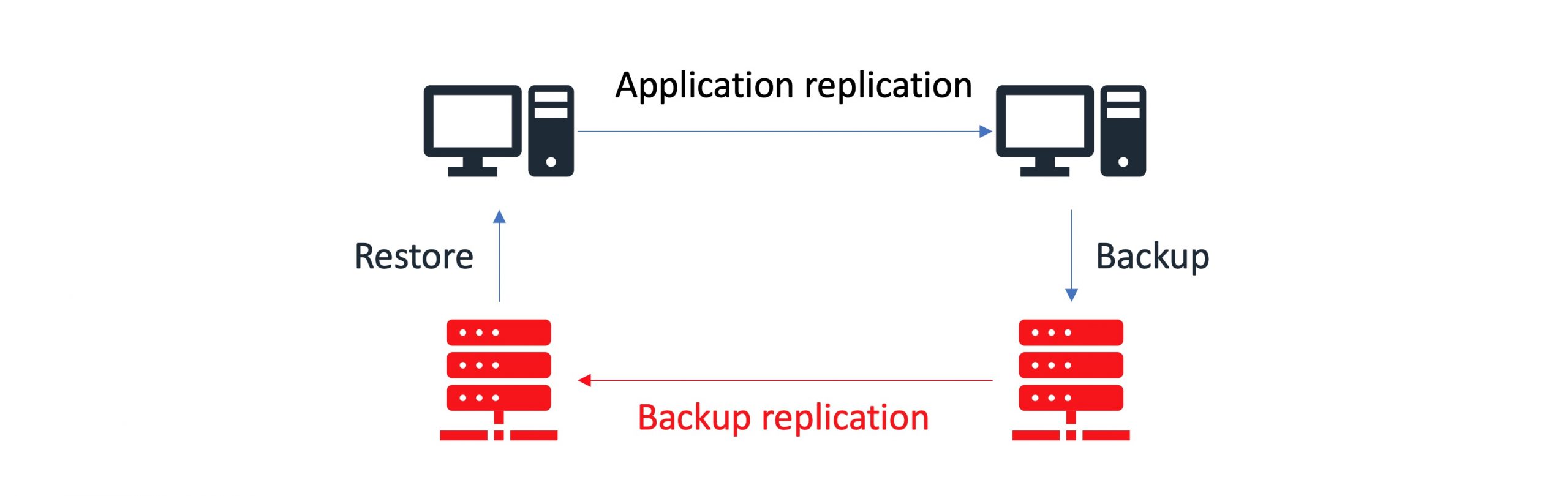
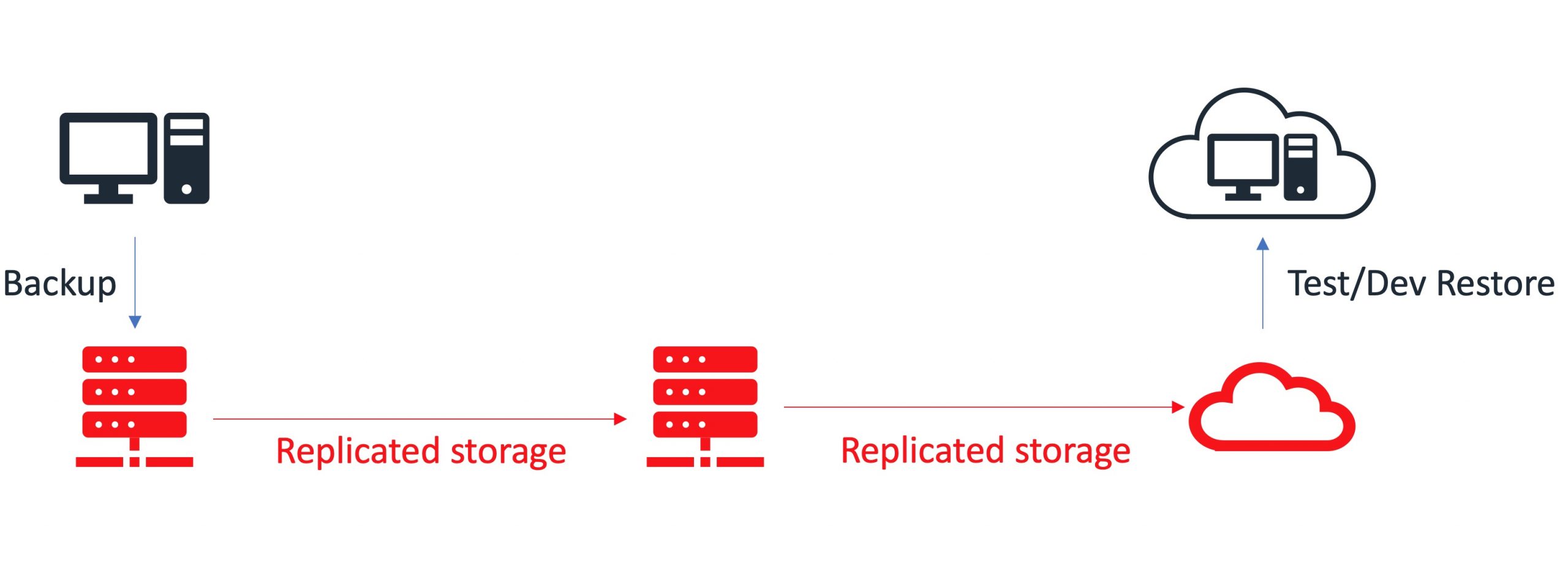
Replicated storage
Replicated storage duplicates data across multiple physical appliances. You can use replicated storage in environments where high-availability and high-reliability are critical.
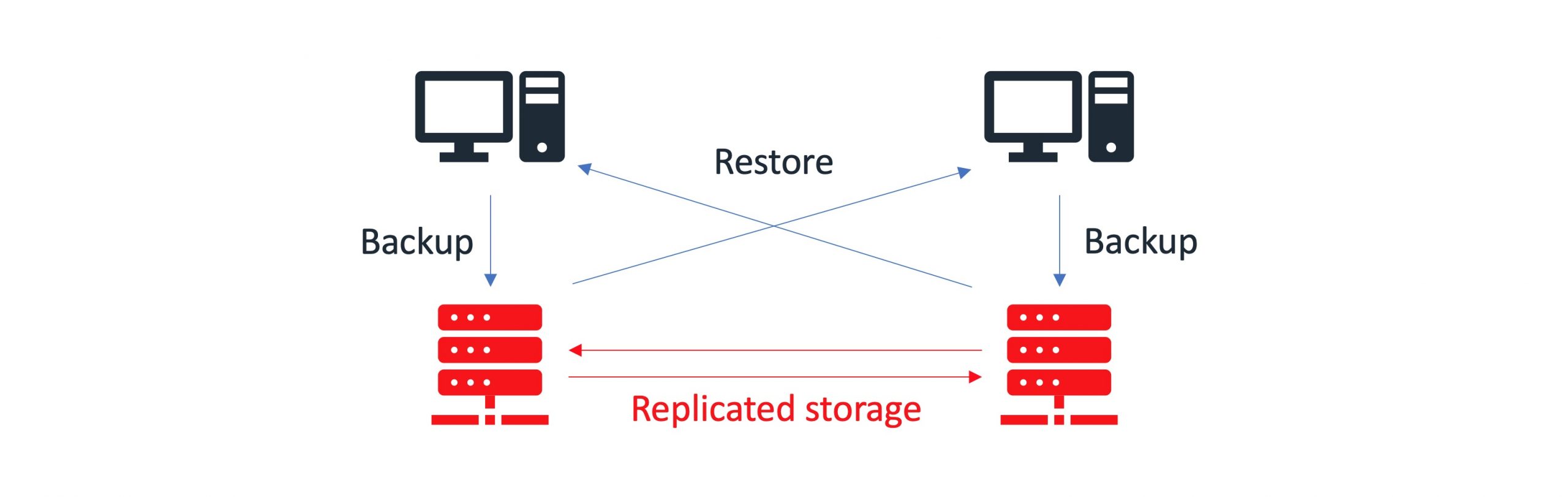
Distributed Replicated storage
Distributed replicated storage diffuses data across replicated physical appliances. You can use distributed replicated storage in environments where the requirement is to scale data store and high-reliability is critical. Distributed replicated volumes also offer improved read performance in most cases.
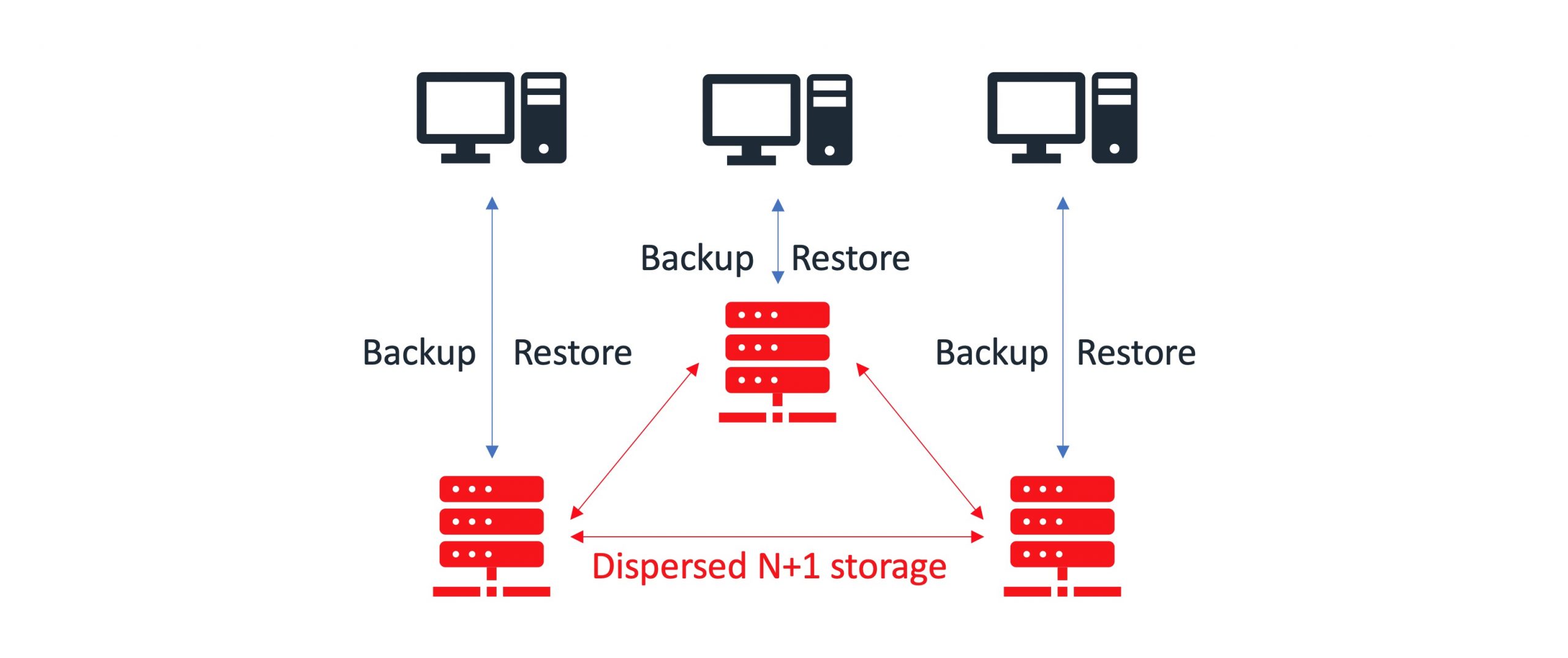
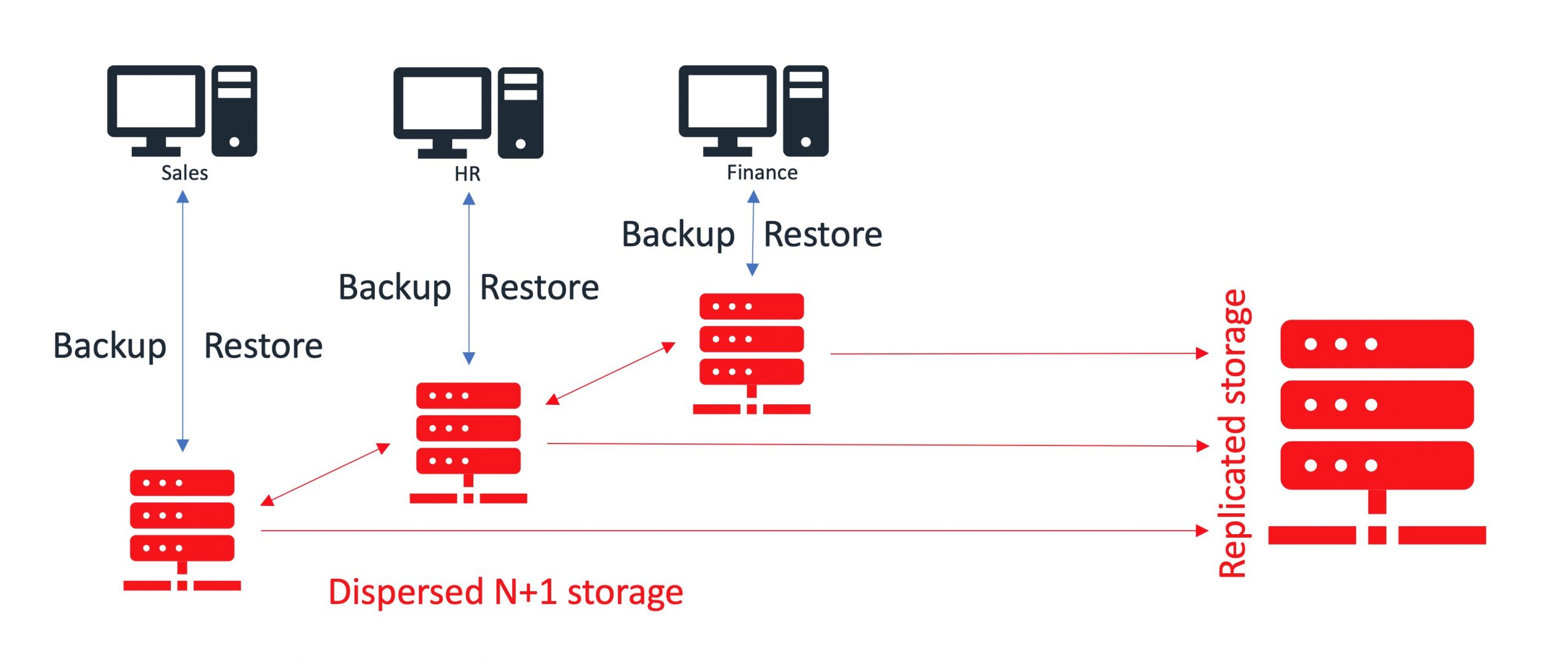
Dispersed storage (N+1, N+2, …)
Dispersed storage is based on erasure codes providing space-efficient protection against appliance failures. Protection algorithm stores encoded fragments of the original data to each appliance in a way that only a subset is needed to recover the original data. The number of appliances that can be missing without losing access to the data can be configured.
Distributed Dispersed storage (N+1, N+2, …)
Distributed dispersed storage diffuses data across dispersed physical devices. This has all of the advantages of distributed replicated storage but additionallydisperses data to gain performance.
You can find sample implementation diagrams of backup architectures presented in the examples below: